















Дубли страниц на сайте – одна из распространенных причин потери трафика. Хотя современные поисковые роботы научились определять основную страницу среди дублей, не стоит всецело полагаться на автоматические алгоритмы. Нередко их выбор отрицательно сказывается на позиции сайта в поисковой выдаче Яндекса и Гугл. Сегодня мы научимся работать с дублями.
Какие страницы называются дублями
Дубли – это страницы одного сайта с разными адресами, но с идентичным содержимым. Под содержимым, в первую очередь, мы понимаем текстовый контент, так как именно на него опираются поисковики при определении копий.
Дубль – это критическая ошибка, которая понижает ранжирование ресурса в поисковой выдаче при продвижении сайта. Поисковые гиганты не жалуют сайты, злоупотребляющие ими.
Какими бывают дубли страниц
В большинстве случаев дубли имеют не только одинаковый текст, но и являются точными копиями друг друга. Такие страницы называются полными дублями. С ними часто приходится бороться СЕО-специалистам.
Также встречаются и частичные дубли. Например, когда авторы копируют часть статьи на другую страницу. Частичные дубли обнаружить гораздо сложнее.
Откуда берутся полные дубли
1. Страницы со слешем и без него:
https://bvorona.su/blog/
https://bvorona.su/blog
2. Адреса с www и без:
https://www.bvorona.su/blog/
https://bvorona.su/blog/
3. Дубли страниц c протоколами http и https:
https://bvorona.su/blog/
http://bvorona.su/blog/
4. Заглавные и строчные буквы в адресной строке:
https://bvorona.su/blog/
https://bvorona.su/BLOG/
5. Цифры в адресе:
https://bvorona.su/blog123/
https://bvorona.su/blog123/888
6. Некорректная настройка страницы с ошибкой 404;
7. Ошибки в заполнении реферальных ссылок и UTM-меток;
8. Одинаковая позиция в нескольких списках (один продукт в нескольких списках);
9. Версии для печати (текст одинаковый, отличается лишь дизайн);
10. Дубли страниц на сайте с незначащими get-параметрами (не влияющими на содержание);
11. Копии со служебными параметрами (появляются при совершении посетителем каких-либо действий).
Не нужно быть профессионалом, чтобы разглядеть полные дубли. Важно вовремя их обнаружить и удалить. Иначе высок риск потери трафика и позиций.
Как появляются частичные дубли
1. Фильтры. Яркий пример – сортировка товара по цене или производителю. Тогда появляется копия оригинальной страницы, но с измененной структурой. Содержимое при этом не меняется;
2. Похожие страницы в каталоге. Когда описание товаров одного назначения просто копируется, а не создается уникальное для каждой позиции. Этим грешат бизнесмены, которые хотят сэкономить на копирайтинге;
3. Пагинация. При большом каталоге она неизбежна, так как иначе пользователю неудобно ориентироваться в большом количестве товаров.
Частичные дубли не сразу влияют на индексирование. Но их трудно обнаружить. Поэтому они – бомба замедленного действия.
Почему вредят дубли страниц
- Ухудшение индексации.
Копии значительно увеличивают вес сайта. Поисковик обрабатывает дубликаты вместо оригиналов. Его производительность ограничена, поэтому он может выдавать посетителю не те элементы. Пользователь может просто не увидеть размещенную на ресурсе информацию.
- Смена страницы в выдаче.
Поисковик из нескольких дублей самостоятельно выбирает ту, которая будет выводиться на соответствующие запросы пользователей. Если его выбор падет на дубликат, а не оригинал, то произойдет снижение позиции всего сайта.
- Некорректная статистика.
Дубли не позволят правильно анализировать сайт. Например, страница в течение продолжительного времени выводится пользователям и обладает хорошей посещаемостью. Но вдруг ее статистика становится нулевой. Во всем виноват дубль страницы, который заменил ее. То есть, согласно статистике, запрос перестал приносить трафик, а по факту – просто сменилась актуальная страница.
- Потеря ссылочного веса.
Если посетитель попадает на дубль, то для поисковика эта страница становится значимее основной. Будут измеряться ее показатели. Когда пользователь захочет поделиться ссылкой, то он опять будет указывать дубль.
Как найти дубли страниц
Способ 1: Яндекс.Вебмастер.
- Заходим в «Страницы в поиске», далее в «Исключенные страницы» и выбираем сортировку по дублям. В результате отображается список дублирующих страниц;
- Переходим в меню «Статистика обхода». В фильтре настраиваем 200-й код. Сервис выдаст страницы, которые доступны поисковику, в том числе и служебные;
- Инструмент «Проверить URL». Если страница перестала выводиться в поиске, то проверка дублей страниц данным методом поможет выявить причину.

Способ 2: Google Webmasters.
Во вкладке «Вид в поиске» выбираем «Оптимизация HTML». Далее ориентируемся на пункты «Повторяющееся метаописание» и «Повторяющиеся заголовки (теги title)». Анализируем ошибки и находим дубли.
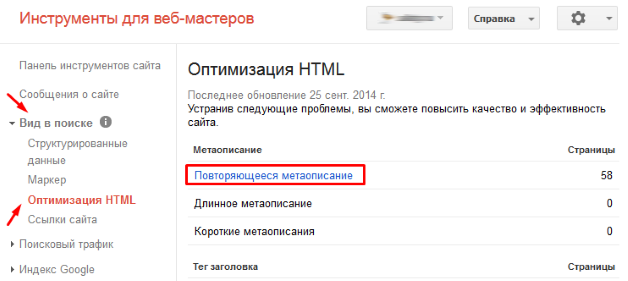
Способ 3: Поисковые системы Яндекс и Google.
- Вводим в поисковую строку оператор site. Подставляем свой домен и заголовок. Например: site: bvorona.su title (для Яндекса), site: bvorona.su intitle (Google). Не забываем про опцию «Показать скрытые результаты». В выдаче ищем нестандартные адреса;
- Для проверки дублей страниц применяем расширенный поиск. В качестве искомого вставляем куски текста. Настраиваем фильтр и анализируем.
Способ 4: Специализированные сервисы.
Используем программы (ComparseR, Xenu, WildShark SEO Spider, Serpstat и другие) для поиска дублей. На сайте запускается бот, который самостоятельно ищет дубли и по окончании показывает отчет обо всех страницах, показавшимися ему подозрительными. Также это можно сделать онлайн с помощью сервиса от отечественных разработчиков по адресу: https://apollon.guru/duplicates/.
Как устранить дубли страниц на сайте.
- Указать канонический адрес страницы.
Если по определенным причинам нельзя просто удалить дубль, то обязательно добавляется атрибут rel=”canonical”. Так мы указываем роботу на главную страницу. Этот метод подойдет для дублей из-за пагинации или клонирования одной позиции в нескольких списках.
- Использовать 301 редирект.
Включаем переадресацию с помощью 301 редиректа с дублей на оригинал. Во многих cms это прописано по умолчанию. Дубли со слешем или без устраняются таким способом.
- Запрет к индексации в robot.txt.
В файле robot.txt помещаются атрибуты, запрещающие индексацию. Это операторы disallow, noindex, clean-param. Так действовать с дублями с незначащими или служебными параметрами, похожими страницами, версиями для печати, фильтрами.
Дубли страниц понижают позицию сайта в поисковой выдаче, уменьшают трафик и даже приводят к санкциям со стороны поисковых систем. Их нужно находить и устранять. Но дубли – это следствие, а не причина. Причина кроется более глубоко – структура, движок, ошибки оптимизации. Работу с дублями лучше доверить профессионалам.
Если Вам понравилась статья - ставим лайк и делимся ей в социальных сетях. Хотите получать больше полезных статей? Подпишитесь на рассылку. Раз в неделю пишем коротко про интернет-маркетинг.






